

บาคาร่า เว็บตรง ฝากถอนไม่มีอั้น ได้เงินจริง ระบบออโต้ 2024
บาคาร่า คือ รูปแบบการเดิมพันที่ได้รับความนิยมอย่างยิ่งในวงการการพนัน ไม่ว่าจะเป็นในสถานที่เดิมพัน เช่น บ่อนคาสิโนสถานที่จริง หรือแม้กระทั่งในโลกออนไลน์ปัจจุบัน โดยผู้เล่นสามารถที่จะเลือกเดิมพันขั้นพื้นฐาน 3 แบบ คือ ผู้เล่น ( player ) และ เจ้ามือ ( banker ) หรือ ถ้าหากเกิด ‘เสมอ’ ที่เรียกอีกอย่างว่า ( tie ) และหากคุณชนะการเดิมพัน คุณจะได้รับเงินเป็นเท่าตัวกับจำนวนที่คุณเดิมพันไว้ 1:1 อย่างไรก็ตามหากคุณเลือกเดิมพันว่าให้เจ้ามือชนะ คุณจะต้องจ่ายค่าคอมมิชชั่น (ค่าต๋ง) แก่ผู้ให้บริการ 5% จากยอดเงินที่คุณเดิมพันไว้ในการเล่น
อีกหนึ่งทางเลือกสำหรับผู้เล่นที่ไม่ต้องการเสียค่าคอมมิชชั่น คาสิโนบางแห่งเสนอ บาคาร่าไม่มีค่าคอมมิชชั่น หรือเรียกว่า “โต๊ะซิก (SIX)” หมายถึง การเดิมพันฝั่งเจ้ามือ เมื่อชนะจะได้เงินเดิมพันเต็มจำนวน ยกเว้น “ชนะด้วย 6 แต้ม” คุณจะโดนหัก 50% หรือครึ่งนึงของเงินรางวัล
นอกเหนือจากนี้ ในกรณีพิเศษ ไม่ว่าคุณเลือกเดิมพันเจ้ามือหรือผู้เล่น แต่มีผล “เสมอ” เกิดขึ้น คุณจะได้รับเงินที่เดิมพันไว้คืน และไม่ต้องจ่ายค่าคอมมิชชั่นเพื่อการเล่น นอกจากสิ่งข้างต้น การเล่นบาคาร่ายังมีเทคนิคพิเศษที่มาช่วยเพิ่มโอกาสให้คุณชนะ เช่น วางเดิมพันตามแผนการที่ถูกต้องตามเส้นทางและการวิเคราะห์สถิติของเกม เป็นต้น แต่สุดท้ายความสำเร็จของการเดิมพันขึ้นอยู่กับความชำนาญในการเล่นและความคิดของแต่ละบุคคลที่เล่นด้วย
แพลตฟอร์มการเดิมพันในยุคสมัยใหม่เล่น บาคาร่า ได้ง่ายๆ
เป็นที่รู้กันอย่างแพร่หลายว่าเกมบาคาร่าเป็นหนึ่งในเกมที่ได้รับความนิยมในสถานที่พนันต่าง ๆ โดยทั่วไป โต๊ะบาคาร่าในคาสิโนมักจะมาในรูปแบบวงรีที่มีผู้แจกไพ่เป็นตัวแทนของเจ้ามือ สิ่งที่ทำให้การเล่นในคาสิโนนั้นมีความน่าสนใจคือผู้เล่นสามารถสนุกกับการพนันได้อย่างอย่างสบายใจ ไม่ว่าจะเป็นเรื่อง เครื่องดื่ม อาหาร แอลกอฮอล์ ผู้หญิง หรือบรรยากาศที่เพื่อสร้างประสบการณ์การเล่นที่ดีเยี่ยม
แม้ว่าผู้เล่นจะพึงพอใจกับสถานที่ที่อยู่อย่างมาก แต่ถึงอย่างนั้นเมื่อต้องการจำเป็นจะต้องเดินทางไปยังคาสิโนซึ่งอาจจะต้องใช้เวลาในการเดิมทาง อาจทำให้รู้สึกไม่สะดวกสบายซักเท่าไหร่นัก ซึ่งอาจส่งผลให้ประสบการณ์การเล่นไม่ได้เหมือนเดิมบางครั้ง ดังนั้น บาคาร่าออนไลน์ ถูกสร้างขึ้นบนแพลตฟอร์มของเว็บไซต์การพนันเพื่อเพิ่มความสะดวกในการเข้าถึงและพัฒนาความสนุกไปอีกขั้นสนุกได้โดยที่คุฯจะอยู่ไหนก็ได้ แค่มีมืถือเพียงเครื่องเดียวก็เพียงพอแล้ว
บาคาร่าออนไลน์ เล่นผ่านระบบออนไลน์ได้ทุกเวลา 24 ชั่วโมง
เกมบาคาร่าออนไลน์ บนเว็บไซต์ของเรามีการแจกเครดิตฟรี ถือเป็นส่วนหนึ่งของคาสิโนออนไลน์ที่ให้บริการอย่างแพร่หลายในปัจจุบัน เว็บไซต์พนันออนไลน์ที่มีอยู่ในปัจจุบัน เพื่อตอบสนองความต้องการของนักการพนันและธุรกิจทุกคน เว็บไซต์พนันออนไลน์ที่เป็นที่นิยม มีความเสถียรและมีควมมั่นคงทางการเงินระดับโลก
เว็บไซต์การพนันออนไลน์ที่มีเกมการเดิมพันทุกรูปแบบ เช่น บาคาร่า สล็อต ไฮโล เสือมังกร รูเล็ต เกมยิงปลา และอื่นๆ ที่สะดวกสบาย ตลอด 24 ชั่วโมง
และแน่นอนว่าเราเป็นเว็บไซต์คาสิโนออนไลน์ที่รวบรวมค่ายเกมมากมาย และให้บริการการพนันตลอด 24 ชั่วโมง รวมถึงระบบฝากถอนที่อัตโนมัติ โดยที่ลูกค้าจะใช้เวลาทำรายการไม่ถึง 30 วินาที ทำให้สมาชิกทุกท่านจะได้รับแต่ประสบการณ์ที่ดีที่สุด ไม่มีสะดุดในทุกปัญหา


ความเป็นมาของ บาคาร่า เว็บตรง ในคาสิโนปัจจุบัน 2024
ในช่วงศตวรรษที่ 1400 เกมบาคาร่า เริ่มต้นใช้ชื่อ “ศูนย์” ในภาษาอิตาลี ในสมัยศตวรรษที่ 1800 เกมได้รับความรู้จักในนาม Chemmy และในอเมริกาชาวท้องถิ่นได้รับรู้จักเกมนี้ในนาม Punto Banco ในช่วงศตวรรษที่ 1850 เกมได้รับการพัฒนาในเนวาดา โดยมีการปรับเปลี่ยนกฎและรูปแบบใหม่เกิดขึ้นในไม่กี่ปีที่ผ่านมา
ในปัจจุบันมีหลากหลายรูปแบบของเกม บาการ่า ที่ผู้คนสามารถเล่นได้ทั้งในคาสิโนแบบดั้งเดิมและคาสิโนออนไลน์ เกมนี้มีความคล้ายคลึงกับเกมป๊อกเด้งของไทย บาคาร่ายังคงเป็นเกมที่ได้รับความนิยมในวงการพนันและมีรูปแบบคาสิโนออนไลน์ต่าง ๆ ที่ให้ความสะดวกสบายให้ผู้เล่น Baccarat Online ยังคงเป็นหนึ่งในเกมที่ได้รับความนิยมอย่างมากในปัจจุบัน
การเดิมพันในรูปแบบไพ่ บาคาร่า รวมความรู้และรูปแบบการเล่น
ถ้าคุณสนใจการ เล่นบาคาร่า แต่ยังไม่เข้าใจกฎและกติกา เรามาดูความรู้เบื้องต้นเกี่ยวกับเกมบาคาร่ากันดีกว่า บาคาร่าเป็นเกมการพนันที่มีวิธีการเล่นง่ายไม่ซับซ้อน และสามารถทำกำไรได้ในทุกวันเมื่อเข้าใจเทคนิคการเล่น การเล่นบาคาร่ามีวิธีการต่างๆ โดยเกมส์นี้มักใช้การคาดเดาโดยส่วนใหญ่ เช่น ในฝั่งของผู้เล่นต้องทายว่าไพ่จะออกที่ฝั่งไหน ความเข้าใจเกี่ยวกับกฎและวิธีการเล่นเป็นสิ่งสำคัญที่ช่วยให้ผู้เล่นมือใหม่ไม่ต้องพึ่งพากับการใช้ดวง
เกมส์บาคาร่า เป็นเกมที่เข้าใจง่ายและยังคงได้รับความนิยมมาตลอดหลายปีที่ผ่านมา เกมนี้มีความเสี่ยงต่ำและสามารถสร้างกำไรให้กับผู้เล่นได้ดี ดังนั้นความรู้เกี่ยวกับ BACCARAT เป็นสิ่งสำคัญที่ช่วยลดความเสี่ยงสำหรับผู้เล่นใหม่ที่ไม่ต้องพึ่งพาดวงในการเดิมพัน
- เมื่อเจ้ามือมีแต้ม 3 และใบที่ 3 ของผู้เล่นได้ 8 จะไม่มีการจั่วเพิ่ม
- เมื่อเจ้ามือมีแต้ม 4 และใบที่ 3 ของผู้เล่นได้ 0, 1, 8, 9 จะไม่มีการจั่วเพิ่ม
- เมื่อเจ้ามือมีแต้ม 5 และใบที่ 3 ของผู้เล่นได้ 0, 1, 2, 3, 4, 5, 8, 9 จะไม่มีการจั่วเพิ่ม
- เมื่อเจ้ามือมีแต้ม 7 จะไม่มีการจั่วเพิ่ม
การเล่นบาคาร่าบน เว็บบาคาร่า มีกฎเกณฑ์ที่ทำให้มันเป็นการพนันที่น่าสนุกมากยิ่งขึ้น มีเทคนิคและรูปแบบการเล่นหลากหลาย เช่น เดิมพันในเกม Tie Game, Player Pair, และ Banker Pair นอกจากนี้การอ่านไพ่ในรูปแบบต่างๆ และการต่อรองมีความสำคัญเช่นกัน ถึงแม้บางส่วนอาจมีบางจุดที่มีความแตกต่างกันไป
เรียนรู้การนับแต้มไพ่ บาคาร่า ก่อนเริ่มเดิมพันจริง
การนับแต้มในเกมบาคาร่าคือวิธีคำนวณคะแนนเบื้องต้นของไพ่ การเล่นบาคาร่ารวมถึงสูตรที่ช่วยในการคำนวณเปอร์เซ็นต์ชนะได้อย่างแม่นยำ เมื่อแจกไพ่เริ่มจากฝั่งผู้เล่นและตามด้วยฝั่งเจ้ามือ แต่ละฝั่งจะได้รับไพ่ 2 ใบ ถ้าต้องแจกไพ่ใบที่ 3 ผลล้มเหลวหรือชนะจะขึ้นอยู่กับไพ่ 2 ใบแรกที่แจก ถ้าแต้มรวมของไพ่ 2 ใบแรกเท่ากับ 8 หรือ 9 ฝั่งหนึ่งได้ 7 แต้ม และอีกฝั่งได้ 6 แต้ม การแจกไพ่ใบที่ 3 จะจ่ายให้ฝั่งที่มีแต้มมากกว่า 5 หรือน้อยกว่านั้น อาจจะจ่ายในฝั่งเดียวหรือในทั้งสองฝั่ง
ในการนับแต้มในบาคาร่า ไพ่ 10, J, Q, K มีค่าเป็น 0 ไพ่ A มีค่าเป็น 1 และสำหรับไพ่ที่เหลือคะแนนจะนับตามตัวเลขที่ปรากฎบนไพ่ การคำนวณแต้มจะตามกฎหลักหรือหลักหน่วย เช่น 3 + 8 + 8 = 19 เท่ากับ 9 หลังจากการคำนวณไพ่แพ้หรือชนะ ระบบบนเว็บจะคำนวณเงินและกำไร และปรับยอดให้เป็นปัจจุบันทุกครั้งที่การเดิมพันสิ้นสุด การเล่น บาคาร่า เว็บตรง เป็นข้อมูลเบื้องต้นที่สำคัญสำหรับมือใหม่ที่สนใจเข้ามาเล่น
สิ่งที่ต้องรู้ก่อนการเดิมพันบน โต๊ะบาคาร่า มีอะไรบ้าง ?
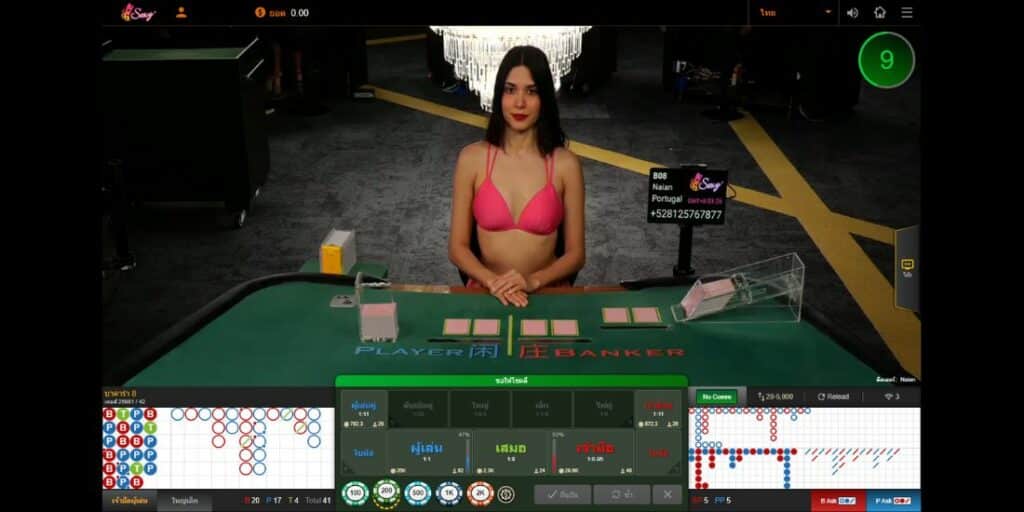
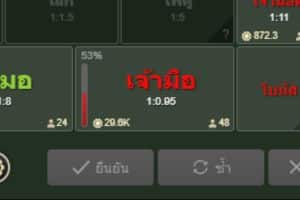
1. เจ้ามือ ( Banker )
การเดิมพันในฝั่ง ” Banker ” หรือ ” เจ้ามือ ” เป็นการเดิมพันที่การทายว่าฝั่ง Banker จะมีแต้มสูงกว่าฝั่ง Player ซึ่งถ้าทายถูกจะถือว่าชนะเดิมพันในรอบนั้น อัตราการจ่ายเงินจะเป็นแบบ แทง1 จ่าย 0.95 หากเกิดเสมอจะคืนเงินเดิมพันให้เต็มจำนวน แต่หากฝั่ง Player มีแต้มน้อยกว่าจะเสียเงินเดิมพันทั้งหมด
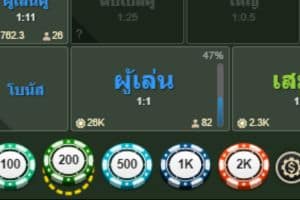
2. ผู้เล่น ( Player )
การลงเดิมพันในฝั่ง ” Player ” หรือ ” ผู้เล่น ” เป็นการทำเดิมพันที่ทายว่าฝั่ง Player จะมีแต้มสูงกว่าฝั่ง Banker ซึ่งถ้าทายถูกจะถือว่าชนะเดิมพันในตานั้นๆ อัตราการจ่ายเงินจะเป็นแบบ แทง1 จ่าย 1 หากเกิดเสมอจะคืนเงินเดิมพันให้เต็มจำนวน แต่หากฝั่ง Player มีแต้มน้อยกว่าจะเสียเงินเดิมพันทั้งหมด

3. เสมอ ( Tie )
การบอก ” เสมอ ” หรือ ” Tie “หมายถึงเมื่อไพ่ที่แจกให้ทั้งสองฝั่ง Player และ Banker มีผลรวมคะแนนเท่ากันในการเดิมพันนั้น อัตราการจ่ายเงินจะเป็นแบบ แทง1 จ่าย 8 (หากเดิมพันในฝั่งอื่นๆ ที่ไม่ใช่เสมอจะคืนเงินทั้งหมด)
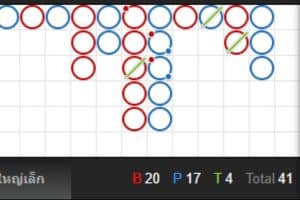
4. Scoreboard
Scoreboard หมายถึงตารางที่ใช้ในการบันทึกสถิติของไพ่ในการเล่นบาคาร่า เพื่อช่วยในการตัดสินใจในการวางเดิมพันต่อไปของผู้เล่น เพื่อเพิ่มโอกาสชนะมากขึ้น หรือใช้ในการนับแต้มของไพ่ต่อไป การบันทึกการเดิมพันจะเรียงลำดับไปจนกว่ารอบการเล่นบาคาร่านั้นจะสิ้นสุด
5. P pair และ B Pair
P pair เมื่อไพ่ที่เปิดในฝั่ง Player เป็นไพ่เหมือนกันและมีแต้มเท่ากัน เช่น Q,Q K,K จะถือเป็น P pair โดยจะมีการจ่ายเงินตามอัตรา แทง 1 จ่าย 11
B Pair เมื่อไพ่ที่เปิดในฝั่ง Banker เป็นไพ่เหมือนกันและมีแต้มเท่ากัน เช่น Q,Q K,K จะถือเป็น B Pair โดยจะมีการจ่ายเงินตามอัตรา แทง 1 จ่าย 11

6. คู่พิเศษ ( Perfect Pair )
Perfect Pair คือเมื่อไพ่ที่เปิดในตานั้นต้องเป็นไพ่คู่ที่เหมือนกันทั้งในฝั่ง Player และฝั่ง Banker พร้อมกัน ถ้าเป็นเช่นนั้นจะถือว่าเป็น Perfect Pair และชนะการเดิมพัน อัตราการจ่ายเงินจะเป็นแบบ แทง1 จ่าย 25
6. ไพ่คู่
ไพ่คู่ เมื่อไพ่ที่เปิดในฝั่ง Player หรือ Banker เป็นไพ่เหมือนกันและมีแต้มเท่ากัน เช่น A A 9 9 จะถือเป็นไพ่คู่ ฝั่งใดก็ได้เพียงแค่ฝั่งเดียวจะถือว่าชนะการเดิมพัน อัตราการจ่ายเงินจะเป็นแบบ แทง1 จ่าย 5
7. Time Zone
Time Zone การใช้นาฬิกาบอกเวลา Real-time ในการแจกไพ่ เป็นวิธีที่ช่วยให้ผู้เล่นสามารถทราบว่าการแจกไพ่เป็นแบบ Live หรือสด และไม่ใช่การเล่นแบบบันทึกวีดีโอ เพื่อเสริมความเชื่อถือในการเดิมพันสำหรับผู้เล่นในการเดิมพัน

8. แถบแสดงอัตราเดิมพันต่างๆ
แถบแสดงอัตราเดิมพันต่างๆ แถบสรุปผลรวมการเดิมพันทั้งหมดของผู้เล่นทุกคนจะแบ่งออกเป็นเปอร์เซ็นต์การเดิมพัน แสดงถึงว่าผู้เล่นมีการลงเดิมพันในการเดิมพันตานั้นๆอย่างไรบ้าง และนำผลลัพธ์สรุปยอดเดิมพันทั้งหมดในตานั้นๆเพื่อให้ผู้เล่นทุกคนทราบ ซึ่งสามารถนำไปใช้ในการตัดสินใจในการเดิมพันตานั้นๆได้
9. ไพ่เล็กและใหญ่ ( Big & Small )
ไพ่เล็กและใหญ่ ( Big & Small ) การเดิมพันในหมวด Big ในเกมบาคาร่าหมายถึงการเปิดไพ่ในรอบนั้นๆและมีการจั่วไพ่เพิ่มขึ้น (5-6ใบ) และวางเดิมพันที่ฝั่ง Player หรือ Banker ฝั่งใดก็ได้ ถ้ามีการแจกไพ่มากกว่า 4 ใบในรอบนั้นๆ จะถือเป็นการชนะเดิมพันในหมวด Big โดยให้อัตราการจ่ายเงินที่ แทง1 จ่าย 0.5 (ไม่รวมทุน) การเดิมพันในหมวด Small ในเกมบาคาร่าหมายถึงการเปิดไพ่ในรอบนั้นๆและไม่มีการจั่วไพ่เพิ่มขึ้นทั้งสองฝั่ง Player หรือ Banker ถ้ามีการแจกไพ่เพิ่มเพียง 4 ใบในโต๊ะ จะถือเป็นการชนะเดิมพันในหมวด Small โดยให้อัตราการจ่ายเงินที่ แทง1 จ่าย 1.5 (ไม่รวมทุน)
10. โบนัส ( Bonus )
Bonus เพื่อเพิ่มความสนุกและความหลากหลายในการเดิมพันเพิ่มเติม เราได้เพิ่มเมนูโบนัสใหม่เข้ามา ในการเดิมพันทั้งสองฝั่ง โดยระบบกติกามีทุกฝ่ายเหมือนกัน แต่จะมีการจ่ายเงินรางวัลในการชนะที่เพิ่มขึ้นตามความต่างของคะแนนไพ่รวมในแต่ละฝั่ง ตัวอย่างจะเป็นดังนี้ เมื่อเลือกชนะที่ผลต่างคะแนนรวมไพ่ของฝั่งที่ต่างกันเป็น 9 แต้ม การชนะนี้จะมีการจ่ายเงินรางวัลที่ แทง1 จ่าย 30 (ตัวอย่างเช่น ถ้า Banker ได้ 9 แต้มจากการเปิดไพ่ 3 ใบ และ Player ได้ 0 แต้มจากการเปิดไพ่ 3 ใบ การเดิมพันที่วางไว้ที่ Banker Bonus จะชนะเดิมพันและจ่ายเงินรางวัล 30 เท่า)
เทคนิคเลือกห้องในการเดิมพัน บาคาร่า ให้ชนะได้ง่ายๆ

เมื่อเล่นบาคาร่าออนไลน์และเลือกห้องที่มีการถ่ายทอดสดแบบเรียลไทม์หรือ สมัครบาคาร่า เว็บไหนดี เลือกโดยดูทิศทางที่ไพ่ออกได้ง่าย และควรรอเปิดไพ่มากกว่า 10 รอบ เนื่องจากสามารถดูสถิติของไพ่ที่ผ่านมาและทำให้ตัดสินใจเดิมพันได้อย่างถูกตามค่าเปอร์เซ็นต์ การเลือกห้องที่เท่าเทียมหรือการเอกไพ่เท่ากัน มีโอกาสทำกำไรสูง เป็นการเดิมพันที่เสี่ยงดวงสูงที่สุด เลือกห้องดีสามารถเพิ่มโอกาสในการเดิมพัน และถ้าคุณชำนาญเล่นจะสามารถเลือกห้องที่ดีและเพิ่มโอกาสได้มากขึ้น เลือกห้องที่เดาไพ่ง่ายๆ เป็นการเล่นอย่างประหยัด และเล่นในห้องที่มีเค้าไพ่ชัดเจนไม่เกิน 3 แบบ เค้าไพ่บาคาร่า ส่วนใหญ่จะมี 4 แบบหลักๆดังนี้
- เค้าไพ่ ” มังกร “
- เค้าไพ่ ” ปิงปอง “
- เค้าไพ่ ” ลูกคู่ “
- เค้าไพ่ ” สองตัดและสามตัด “
การเดาไพ่เป็นเรื่องง่ายเพราะเค้าไพ่แบ่งชัดเจน การวิเคราะห์ชนะหรือการจ่ายรางวัลเป็นสิ่งสำคัญ หากเลือกห้องที่ไม่มีสถิติการเล่นจะทำให้เล่นยากขึ้น ดังนั้นการเลือกห้องเป็นเทคนิคที่สำคัญที่สุด นอกจากนี้ยังมีวิธีอีกหนึ่งวิธีในการเลือกห้องอย่างง่ายๆ คือการเลือกห้องที่มีมังกร เพราะเค้าไพ่มังกรเข้าใจง่ายที่สุด ช่วยให้ชนะได้อย่างสบายใจ นอกจากนี้ยังเล่นง่ายและได้กำไรมาก นักเดิมพันที่ชำนาญมักชอบห้องมังกรเพราะมักจะออกไพ่ฝั่งเดียวกันหลายรอบ แต่ต้องระวังอย่าแทงสวนเด็ดก่อนที่ไพ่จะเปลี่ยนฝั่ง นักเดิมพันทั้งหลายมักได้กำไรจากห้องมังกรอย่างง่ายๆ หากไม่แน่ใจว่าจะเล่นที่ฝั่งใด สามารถหาห้องมังกรใหม่เพื่อเล่นต่อได้อีก
เทคนิคการอ่านไพ่ บาการ่ารู้ไว้ไม่ผิดหวัง โอกาศชนะสูง
บาคาร่าเว็บตรง ที่เปิดเข้าใช้ง่ายมักมีเค้าไพ่และวิธีการอ่านต่างๆ มือใหม่ควรศึกษาก่อนที่จะวางเดิมพัน การเล่นให้ได้กำไรเป็นสิ่งสำคัญและเป็นไปได้หากศึกษาการเล่นต่างๆ ในปัจจุบันเรามาสอนวิธีการเล่นและการอ่านเค้าไพ่อย่างง่าย วางเป้าหมายกำไรให้เข้ากับเงินทุนแต่ละวัน เพื่อช่วยให้ผู้เล่นสามารถจัดการเงินได้ ลดความเสี่ยงในการขาดทุนในการเล่น การตั้งเป้าหมายชัดเจนช่วยให้สามารถเล่นได้อย่างไม่ต้องกังวล หากทุนตั้งไว้หมด ควรหยุดเล่นทันที การมีสติและเย็นชื่นใจในการเล่นมีผลต่อผลลัพธ์เช่นกัน เพราะบางครั้งการเล่น บาคารา อาจทำให้เสียติดกันหลายครั้ง
การขาดสติในการเล่นอาจทำให้เสียมากขึ้น ควรระมัดระวังว่าอาจจะต้องเปลี่ยนโต๊ะเพื่อศึกษาจังหวะไพ่ หาแต่ละโต๊ะที่เหมาะกับตัวเอง เพื่อลดการขาดสติในการเล่น การเดิมพันแบบทบต้องเพิ่มเงินทุน เพราะยิ่งเสียเงินคุณจะต้องเพิ่มเงิน การเดิมพันแบบทบอาจจะทำให้เสียครึ่งต่อครึ่ง วิธีนี้มักใช้กันโดยนักเดิมพันชำนาญแต่ไม่ค่อยเหมาะสำหรับมือใหม่ การใช้โปรแกรมคำนวณ แทงบาคาร่า สามารถช่วยประมวลผลผลความน่าจะเป็นในการลงไพ่ต่อไปได้ ทำให้ตัดสินใจได้ง่ายขึ้นสำหรับผู้เล่นทั่วไปที่ต้องการความสะดวกสบายในการเล่นแบบอัตโนมัติ
การอ่านเค้าไพ่ในบาคาร่ามีลักษณะที่แตกต่างกันไปดังนี้
- เค้าไพ่มังกร: การออกไพ่ติดต่อกันในฝั่งใดฝั่งหนึ่งเป็นระยะเวลานาน มีความง่ายต่อการอ่าน แต่ก็มีความลับที่มากพอสมควรที่อาจหลอกนักเดิมพันได้มาก
- เค้าไพ่ปิงปอง: การออกไพ่ค่อนข้างสับสนเมื่อฝั่งเจ้ามือออกก่อนแล้ว ไพ่จะสลับกันไปเรื่อยๆ แต่ไพ่สามารถเปลี่ยนเป็นลักษณะอื่นได้เช่นกัน ผู้เล่นต้องมีความชำนาญอย่างเหมาะสม
- เค้าไพ่สองตัวตัด: การออกไพ่จะมีการชนะติดต่อกันฝั่งใดฝั่งหนึ่งชนะไม่เกิน 2 ครั้ง ในช่วง 30 ตาแรก หากมีการออกเจ้ามือชนะติดต่อกันไม่เกิน 2 ครั้ง จะไม่มีการชนะครั้งที่ 3 ผู้เล่นควรมีความสติในการติดตามไพ่ในแต่ละรอบ
- เค้าไพ่ลูกคู่: การออกไพ่จะมีการชนะติดต่อกัน ฝั่งใดฝั่งหนึ่งเป็นคู่ๆ จะสลับกันไปเรื่อยๆ จนกว่ารูปแบบไพ่จะเปลี่ยนแปลงในแต่ละรอบ
สมัครบาคาร่า เว็บบาคาร่า แค่ง่ายๆ ไม่กี่ขั้นตอนเท่านั้น
การ สมัครบาคาร่า ผ่านแพลตฟอร์มในปัจจุบันง่ายมากเพียงไม่กี่ขั้นตอนโดยไม่จำเป็นต้อง Add Line เพื่อแจ้งข้อมูลส่วนบุคคลให้กับทางแอดมินอีกต่อไป การพัฒนาระบบให้สามารถสมัครสมาชิกผ่านเว็บไซต์ช่วยเพิ่มความเป็นส่วนตัวและลดความล่าช้าและความผิดพลาดจากแอดมินให้น้อยลง ด้วยการใช้เวลาสมัครสมาชิกไม่ถึง 5 นาที เรามีระบบฝาก-ถอนไวและอัตโนมัติ 100% วิธีการดำเนินการเหล่านี้ประกอบด้วยดังนี้
- เข้าสู่เว็บไซต์ ” เว็บบาคาร่าออนไลน์ “
- คลิกที่ปุ่ม “สมัครสมาชิก”
- กรอกข้อมูลส่วนบุคคลเพื่อยืนยันข้อมูล
- รับรหัส OTP ผ่านทางโทรศัพท์มือถือของคุณ
- กำหนดรหัสผ่านและเสร็จสิ้นการสมัครสมาชิกพร้อมใช้งาน
เพียงทำตามขั้นตอนเหล่านี้คุณสามารถเข้าเล่นและดำเนินการฝากถอนได้ทันที คำแนะนำเล็กๆ คือควรเก็บรักษารหัสผ่านของผู้ใช้อย่างปลอดภัยเพื่อป้องกันการรั่วไหลของข้อมูล หากผู้ดูแลระบบต้องการเข้าถึงบัญชีผู้ใช้ของคุณเพื่อแก้ไขปัญหาใด ๆ ทางผู้ดูแลระบบจะแจ้งให้คุณทราบอยู่เสมอ

บาคาร่าออนไลน์ จำเป็นต้องระมัดระวังในการเล่น และควรศึกษาข้อมูลให้ดี
เมื่อเข้าร่วม เกมบาคาร่า ควรศึกษาข้อมูลและคู่มือเกี่ยวกับการเล่นไพ่ เข้าใจข้อมูลเหล่านี้จะช่วยลดความเสี่ยงในการเล่นผิดและสูญเสียทุน การจดจำข้อมูลเกี่ยวกับบาคาร่าเป็นสิ่งสำคัญสำหรับการวางเดิมพันในแต่ละรอบ การวิเคราะห์ตารางผลการแข่งขันมีบทบาทในการตัดสินใจในการวางเดิมพันอย่างง่ายดายหรือจะใช้ สูตรบาคาร่า ในการเดิมพันก็สามารถทำได้ หรือแม้แต่เข้าใจตารางการเล่นไพ่บาคาร่า เช่น ตารางไข่ปลา ตารางไม้ขีด และ ตารางซาราเปา เป็นสิ่งสำคัญที่ช่วยให้การเล่นเป็นไปอย่างราบรื่น นอกจากนี้ การเข้าใจดวงของผู้เล่นก็เป็นสิ่งสำคัญ เกมบาคาร่าถือเป็นเกมเสี่ยงโชค ซึ่งความเชื่อทางวิจารณญาณเป็นสิ่งจำเป็นในการเล่น
เมื่อต้องการเข้าร่วมเล่นเกมบาคาร่า ได้เงินจริง ควรระมัดระวังว่าไม่มีสูตรการเล่นที่แน่นอน ข้อสำคัญที่ต้องระมัดระวังคือความจำเป็นต้องมีความรู้ที่เกี่ยวข้อง หากผู้เล่นพึ่งอยู่กับความเชื่อดวงเท่านั้นโดยไม่มีความรู้ใดๆ เกี่ยวกับ ” บาคาร่า ” อาจทำให้เกิดการสูญเสียเงินทุนหรือเสี่ยงพ้นไปได้ การเล่นเกมอาจต้องรวดเร็วซึ่งอาจทำให้ต้องตัดสินใจโดยเร่งด่วน ซึ่งอาจนำไปสู่การสูญเสียโดยไม่รู้ตัว ดังนั้น ผู้เล่นควรวางแผนเริ่มต้นล่วงหน้า หากเกิดเหตุการณ์เช่นนี้ การเล่นควรเป็นไปอย่างระมัดระวัง หากผู้เล่นเร่งรีบลงในการพยายามที่จะรวดเร็วเพื่อได้กำไรมากขึ้น อาจเสี่ยงไปเกินกว่าที่ควร หากได้กำไรที่น่าพอใจแล้ว ควรหยุดเล่นทันที มิฉะนั้น อาจเสี่ยงเสียเงินมากกว่าที่ได้กำไรไปด้วย
เดิมพันตรงกับ บาคาร่าเว็บตรง สนุกทำกำไรได้ทุกวัน
กำไรในการเล่น บาคาร่าสายฟ้า อาจเป็นไปได้มากหรือน้อยขึ้นอยู่กับดวงการเล่น และความรู้ที่มี เริ่มต้นด้วยทุน 50 – 100 บาท โดยเริ่มต้นการเดิมพันตามความเข้าใจของเค้าไพ่เบื้องต้น ด้วยเค้าไพ่ที่เรียกว่ามังกร เป็นที่เข้าใจสำหรับผู้เล่นที่ใหม่ เริ่มต้นด้วยการวิเคราะห์ตารางสถิติ หากมีฝั่งใดชนะมากกว่า 4 ครั้งติดต่อกัน ให้ผู้เล่นเดิมพันด้านที่ชนะ ต่อเนื่องไปจนกว่าอีกฝั่งจะชนะ แล้วควรหยุด ควรลงเดิมพันที่ระดับต่ำก่อน หากได้กำไรมากพอแล้วอาจเพิ่มเงินเดิมพันเป็นละเอียด ถ้าผู้เล่นไม่แน่ใจว่าจะเดิมพันด้านไหน เราแนะนำให้รอสำหรับรอบถัดไป เพราะการเดิมพันโดยไม่มั่นใจอาจทำให้ไม่ได้กำไรเลย การเดิมพันในทุกครั้งควรรอให้มั่นใจก่อนที่จะดำเนินการ
ผู้เล่นควรมีความมั่นใจและสติในการเดิมพัน สามารถเปลี่ยนห้องได้ตลอดเวลาจนกว่าจะพบกับห้องที่สามารถทำกำไรได้มาก เพราะหากยังอยู่ในห้องเดิม อาจทำให้ไม่มีโอกาสทำกำไร หรือ อาจเสี่ยงทำให้เสียเงินได้ การเลือกห้องควรพิจารณาจากการวิเคราะห์สถิติการชนะแพ้ในรอบ 10 ครั้งขึ้นไป หากผู้เล่นได้กำไรตามที่ต้องการแล้ว แนะนำให้ถอนเงินไปก่อน ไม่ควรเล่นต่อ เพราะอาจเสี่ยงทำให้เสียเงินมากขึ้น หากต้องการเดิมพันต่อ ควรถอนกำไรก่อนแล้วค่อยลงเดิมพันใหม่ การเล่นบาคาร่าสามารถทำกำไรได้จริง หากผู้เล่นศึกษาวิธีต่างๆที่แนะนำไว้ การทำกำไรทุกวันไม่ยากเลย
มีหลายค่ายให้เลือก บาคาร่าออนไลน์ เหมาะสำหรับมือใหม่หรือไม่ ?
การเล่นเกมเป็นเรื่องที่น่าสนใจมาก โดยเฉพาะสำหรับผู้เล่นมือใหม่ที่อาจจะเคยเห็นผู้คนอื่นๆ ที่กำลังโพสต์เรื่องกำไรบนโซเชียลมีเดีย เช่น Facebook, Twitter หรือแพลตฟอร์มอื่นๆ จริงๆแล้ว ไม่มีใครจะมาแชร์ข้อมูลอย่างนั้นโดยที่ไม่มีเจตนาที่จะได้รับสิ่งใดกลับมา ส่วนมากของผู้โพสต์จะใช้เทคนิคการส่งสูตรพร้อมลิงค์สมัครเว็บพนัน ซึ่งหมายความว่าคุณจะต้องตามเล่นบนเว็บที่เขาแนะนำ หรือในกรณีอื่นๆ อาจต้องจ่ายค่าใช้จ่ายโดยไม่ระบุ เช่น ค่าถอนกำไร ซึ่งอาจทำให้คุณต้องใช้เงินอย่างต่อเนื่อง ดังนั้นเราแนะนำให้ ทดลองเล่นบาคาร่า จะดีกว่าเพราะท่านสามารถหาเว็บที่มีความเชื่อถือได้อย่างง่ายดาย การเล่นในยุคปัจจุบันง่ายมากๆ และมีข้อมูลที่เป็นประโยชน์อย่างเพียงพอในการช่วยในการตัดสินใจของท่าน
การเรียนรู้เทคนิคจากผู้เชี่ยวชาญหลายท่านสามารถช่วยให้คุณสร้างกำไรได้อย่างมีประสิทธิภาพ โดยไม่จำเป็นต้องมี สูตรบาคาร่า คุณสามารถทำได้โดยการสังเกตการเล่นไพ่หรือใช้ดวงในการเล่นบาคาร่าบางส่วน หากมีสูตรในการแทงเสมออยู่ ก็จะช่วยเพิ่มโอกาสให้คุณได้กำไรมากขึ้น คุณสามารถเรียนรู้สูตรได้จากบทความที่เคยระบุไว้ เพราะคุณสามารถดูสถิติและย้อนหลังได้อย่างง่ายดาย วิธีการเล่นที่ดีคือการสังเกตผลลัพธ์ที่มักจะเกิดขึ้นในลักษณะเดียวกัน เช่น มักจะมีฝั่งผู้เล่นที่มาแรงกว่าหรือชนะบ่อยกว่าส่วนอื่นๆ ในกรณีเช่นนี้ คุณควรที่จะวางเดิมพันบนฝั่งผู้เล่นมากกว่าการเดิมพันอื่นๆทั้งหมด
ค่ายคาสิโนออนไลน์ยอดฮิตที่ได้รับความนิยมในไทย
การเลือกค่ายคาสิโนออนไลน์สำหรับผู้เล่นใหม่อาจเป็นเรื่องที่ท้าทาย เนื่องจากมีการแข่งขันระดับสูงในตลาด เกมไพ่ ออนไลน์ และมีหลากหลายเว็บที่สามารถเลือกเล่นได้ในปัจจุบัน ตัวอย่างเว็บที่น่าสนใจและได้รับความนิยมอย่างแพร่หลายเช่น Sa Gaming, Wm Casino, Pretty Gaming, AE Gaming, ae sexy, dg casino, sexy baccarat ฯลฯ แต่คุณอาจต้องลองเล่นเพื่อค้นหาค่ายที่เหมาะสมที่สุดตามความต้องการและสไตล์การเล่นของตัวเอง และไม่ได้มีเพียงแค่นี้เท่านั้นยังมี เซ็กซี่บาคาร่า แทงบอล ไฮโล รูเล็ต และอื่นๆ
